
[ALOHA] Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Authors : Tony Z. Zhao, Vikash Kumar, Sergey Levine, Chelsea Finn
Institute : Stanford University, UC Berkeley, Meta
Year : 2023
Paper : https://arxiv.org/abs/2304.13705
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Fine manipulation tasks, such as threading cable ties or slotting a battery, are notoriously difficult for robots because they require precision, careful coordination of contact forces, and closed-loop visual feedback. Performing these tasks typically requ
arxiv.org
Project website : https://tonyzhaozh.github.io/aloha/
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Please do not re-share this URL yet! We will release it soon ; ) --> Abstract. Fine manipulation tasks, such as threading cable ties or slotting a battery, are notoriously difficult for robots because they require precision, careful coordination of contact
tonyzhaozh.github.io
Summary
- Teleoperation Interface: A low-cost, open-source hardware system that enables fine-grained bimanual manipulation by capturing real human demonstrations.
- Imitation Learning: Employs Action Chunking with Transformers (ACT) to learn robust, precise dual-arm control policies directly from demonstration data.
Key words: teleoperation, imitation learning, dual manipulation, precise manipulation, low-cost, open-source
Abstract & Introduction
- 해당 논문은 높은 정밀도를 요구하는 manipulation task에 대해서 인공지능 모델의 학습을 통해 가격이 저렴하고 상대적으로 부정확한 하드웨어를 사용해 해결하는 것이 가능한지에 대해 기술함
- 위의 문제를 해결하기 위해 간단하지만 새로운 알고리즘인 Action Chunking with Transformers(ACT) 를 사용함
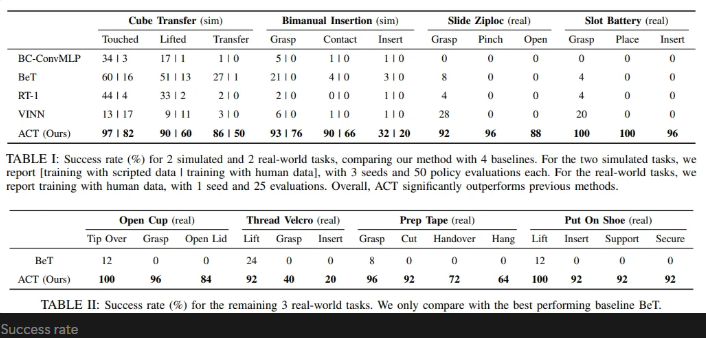
- 해당 알고리즘을 사용했을 때 6가지의 task에서 10분간의 시연을 통해 80~90%의 성공률을 확인함
Teleoperation System
- 저가형 시판 매니퓰레이터 두 세트를 사용함.
- 각 세트의 매니퓰레이터는 Joint-space mapping을 적용하여 원격으로 조작됨.

Imitation Learning Algorithm → ACT
- RL에서 정밀성과 시각적 피드백이 요구되는 작업은, 고품질의 데이터가 제공되어도 상당한 도전일 수 있음.
- 예측한 작은 error로 인해 실제 상태에서 큰 차이를 초래할 수 있고, 이는 compounding error 문제를 악화시킴
- 위 문제를 해결하기 위해 action chunking을 적용함.
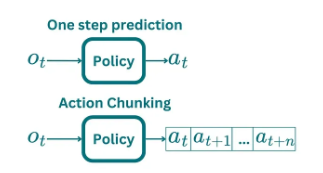
- single step을 예측하는 policy가 아닌 향후 k step 동안의 joint position을 예측하는 policy를 사용함.
- 위 방식을 통해 effective horizon, 즉 step에 소요되는 시간을 k 만큼 줄이게 되고 compounding error를 완화
- 또한 행동의 sequence를 예측함으로서, Markovian single-step policy로는 모델링하기 어려운, 시연 중 발생하는 pause, temporally correlated confounders를 해결하는 데 도움을 줌.
- Policy의 부드러움을 향상시키기 위해 추가로 temporal ensembling을 제안함
- Temporal ensembling은 policy query 주기를 높이고, overlapping action chunk를 평균냄.
- 위에서 정리한 Action-chunking policy를 Transformer를 활용하여 구현함.
- 또한 human-data의 변동성을 포착하기 위해 Conditional VAE(CVAE)로 학습함.
- 위의 방식을 *Action Chunking with Transformers (ACT)*라고 함.
Action Chunking with Transformers
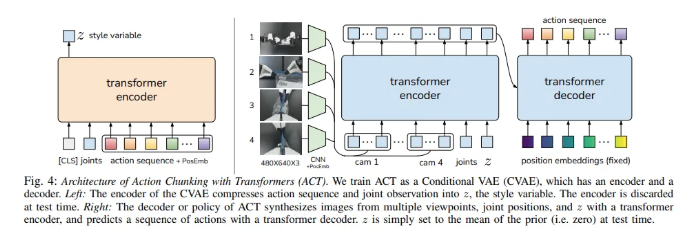
- 사람이 만든 데이터는 비정형적이고 확률적임. 이를 CVAE(생성형 모델)를 사용하여 해결함.
- ACT를 Conditional VAE (CVAE, Conditional Variational Autoencoder)로 학습함.
- CVAE의 encoder는 action sequence와 joint observation을 $z$ 로 압축함.
- Encoder는 test에서는 버림.
- ACT의 decoder는 Transformer encoder를 사용하여 image, joint posision, 그리고 $z$ 를 사용하여 decoder에서 sequence of action(다음 스텝에서 양 팔의 joint position)을 예측함
- Observation : follower robot’s joint positions, image feed (4 camera images)
ACT Training & Inference

- Action Chunking (AC) : chunk size를 $k$ 로 고정하고 진행함. $k$ 스텝마다 observation을 받아 다음 $k$ 스텝의 action을 수행함.
- 단순한 AC 구현으로는 새로운 환경의 observation이 $k$ 스텝마다 반영되어 jerky(덜 부드러운, 튀는)한 현상이 발생할 수 있음.
- Temporal Ensenble (TE) : 매 스텝마다 $k$ 스텝 만큼의 예측을 수행함.
- CVAE (Conditional Variational Autoencoder)
- Encoder : 현재의 관측값과 행동 시퀀스를 입력으로 받아, diagonal gaussian으로 매개변수화된 스타일 변수 $z$의 분포의 평균과 분산을 예측함. CVAE decoder를 학습시키 위해서만 사용되며, 테스트 시에는 버려짐. 학습 속도를 높이기 위해 observation은 생략하고 proprioceptive observation과 행동 시퀀스만 조건화 함.
- Decoder : $z$와 현재의 observation(image, joint position)을 조건으로 하여 action sequence를 예측함. 테스트 시에는 $z$를 사전 분포의 평균(0)으로 설정하여 결정론적으로 디코딩함.
Limitation
- 하드웨어 자체의 한계
- perception 정도, data의 양에 따라 실패 가능성 있음
- Candy wrapper open, ziploc bag open etc.